Data Engineering
Real-Time Ad Analytics Platform
A distributed analytics platform designed for ingesting, processing, and reporting user and advertisement event data with near real-time visibility.
System Architecture
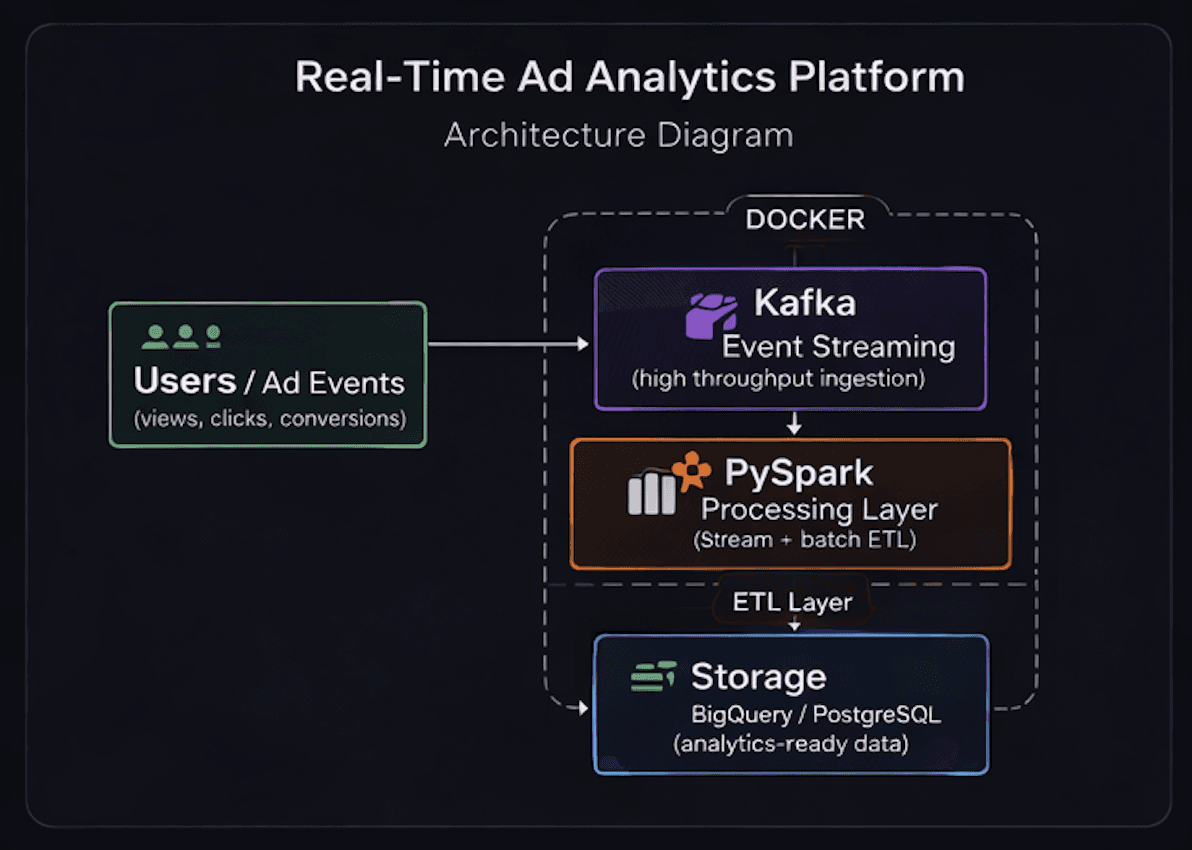
Problem Statement
Traditional batch reporting creates delays in campaign visibility and makes it difficult to monitor user interaction and ad performance in real time. This project was built to support scalable streaming ingestion and fast analytical processing for event-driven reporting.
Tech Stack
KafkaPySparkDockerPostgreSQLBigQuery
Key Contributions
- Built a streaming data pipeline for ingesting user and advertisement event streams
- Implemented PySpark-based processing for scalable transformations across streaming and batch workflows
- Designed analytics-ready storage patterns to support performance reporting and campaign analysis
Results
- Enabled near real-time processing of event data
- Structured the pipeline for both streaming and batch analytics use cases
- Improved reporting readiness through optimized transformation and storage design
Engineering Decisions
- Used Kafka as the ingestion backbone to handle decoupled event streaming
- Chose PySpark to support scalable transformations instead of limiting the system to lightweight local scripts
- Separated ingestion, processing, and storage responsibilities for better maintainability
Challenges Faced
- Coordinating multiple services in a reproducible local environment required careful Docker setup
- Designing schemas for both raw events and analytics-ready outputs required tradeoffs between flexibility and query performance
- Balancing streaming realism with project-level infrastructure constraints required simplifying some components without breaking the architecture